Figure 1. (Left) Robotic visual instruction is a hand-drawn approach for commanding robots, utilizing circles and arrows to convey task definition. In long-horizon tasks, green and blue sketches denote the first and second task steps, respectively. (Right) It illustrates the action sequences output via VIEW. Our method exhibits robust generalization to real-world manipulation tasks, including (a) trajectory-following tasks, (b) cluttered environments with disturbances, and (c) multi-step operations.
Recently, natural language has been the primary medium for human-robot interaction. However, its inherent lack of spatial precision for robotic control introduces challenges such as ambiguity and verbosity. To address these limitations, we introduce the Robotic Visual Instruction (RoVI), a novel paradigm to guide robotic tasks through an object-centric, hand-drawn symbolic representation. RoVI effectively encodes spatial-temporal information into human-interpretable visual instructions through 2D sketches, utilizing arrows, circles, colors, and numbers to direct 3D robotic manipulation. To enable robots to understand RoVI better and generate precise actions based on RoVI, we present Visual Instruction Embodied Workflow (VIEW), a pipeline formulated for RoVI-conditioned policies. This approach leverages Vision-Language Models (VLMs) to interpret RoVI inputs, decode spatial and temporal constraints from 2D pixel space via keypoint extraction, and then transform them into executable 3D action sequences. We additionally curate a specialized dataset of 15K instances to fine-tune small VLMs for edge deployment, enabling them to effectively learn RoVI capabilities. Our approach is rigorously validated across 11 novel tasks in both real and simulated environments, demonstrating significant generalization capability. Notably, VIEW achieves an 87.5% success rate in real-world scenarios involving unseen tasks that feature multi-step actions, with disturbances, and trajectory-following requirements. Code and Datasets in this paper will be released soon.
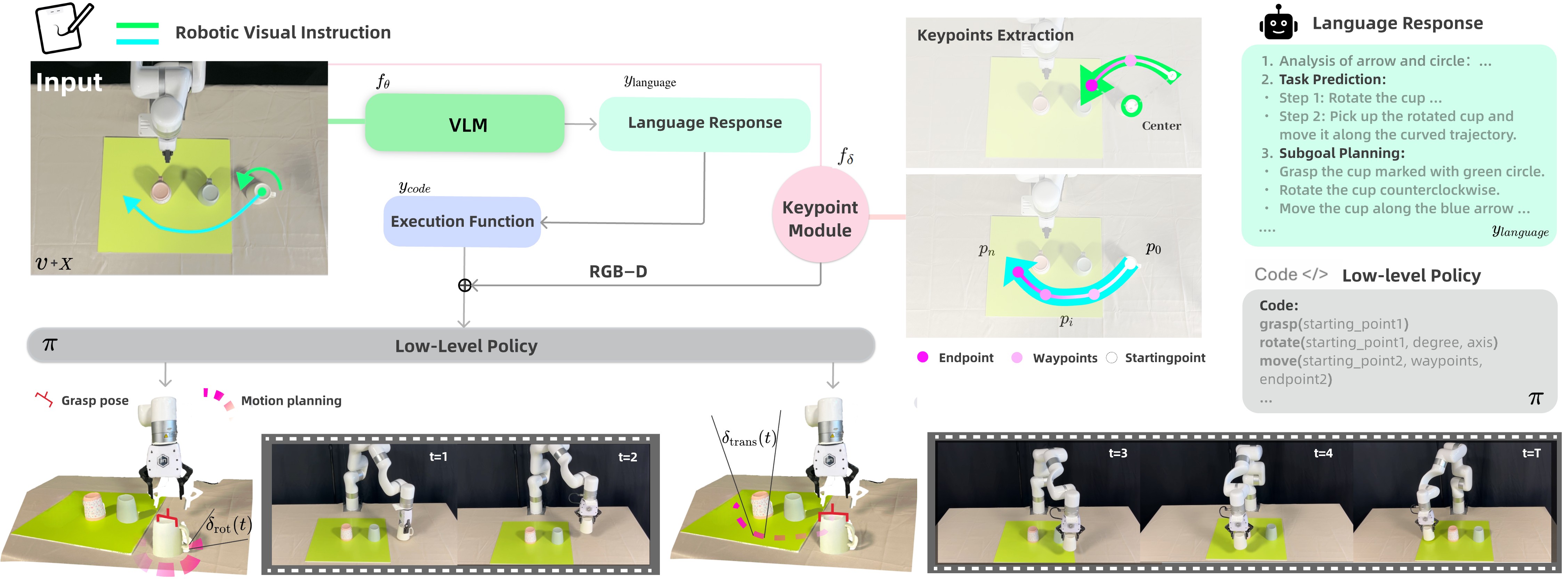
Figure 2. VIEW Architecture. This pipeline begins with a visual instruction drawn onto the initial observation. The VLM generates hierarchical language-to-action outputs, including task definition, detailed planning, and executable functions. The executable functions are then combined with keypoints extracted from the keypoint module and passed to a downstream low-level policy, which enables the robotic arm to execute each action step-by-step. This approach bridges hand-drawn visual instructions with precise robotic actions.
@article{li2025robotic,
title={Robotic Visual Instruction},
author={Li, Yanbang and Gong, Ziyang and Li, Haoyang and Huang, Xiaoqi and Kang, Haolan and Bai, Guangping and Ma, Xianzheng},
booktitle={arXiv preprint arXiv:2505.00693},
year={2025},
}
